生成AI活用が進まない7つの理由|情シスの“次の一手”とは?
「結局、生成AI活用って社内で進んでないよね」
PoC(概念実証)まではやったが本番導入に至らない、導入しても使われない、効果が測れない——現場の情報システム部門や経営者がそう感じるのは珍しくありません。
この記事では、生成AI活用が進まない理由を“あるある”で終わらせず、情報システム部門が稟議・設計に使える判断材料として整理します。具体的には次の3点が持ち帰れます。
- 生成AI活用が進まない「7つの理由」と、どこで詰まっているかの切り分け方
- セキュリティ/運用/ガバナンスの論点を落とし込む設計観点(最小限)
- PoC止まりから抜けるための導入ステップと、チェックリスト

目次
背景:日本企業で「進まない」のは自然。むしろ“止まる構造”がある
生成AIは、SaaS導入のように「アカウントを配って終わり」になりにくい領域です。理由はシンプルで、生成AIは社内データ・業務手順・権限・監査・責任分界に触れるからです。
つまり「試す」のは簡単でも、「業務として回す」には設計と運用が必要になります。ここを飛ばすと、PoC止まりになるケースがあります。
生成AI活用が進まない7つの理由(経営/情報システム部門/現場の共通課題)
理由1:PoCの目的が“体験”で終わり、成功条件が定義されていない
よくあるのが「とりあえず使ってみた」「便利そうだった」でPoCを閉じるパターンです。稟議・本番化に必要な材料(効果、リスク、運用)が残りません。
- 失敗の兆候:PoC成果物がデモ動画と感想だけ/現場の工数削減が測れていない
- 対策:KPIを3つに絞る(例:作業時間、一次回答率、差し戻し率)+運用面のKPI(例:問い合わせ件数、誤出力率)も置く
理由2:ユースケースが“汎用AIでやること”になり、業務プロセスに刺さらない
議事録要約、メール文面作成などは入口として良い一方、差別化しにくく「使っても使わなくても変わらない」状態になりがちです。現場定着には、業務プロセスの“詰まり”に直撃させる必要があります。
- 刺さりやすい例:社内規程・過去案件・手順書を根拠付きで引ける一次対応/申請内容の不備検知/運用手順の自動チェック
- 設計の要点:入力(トリガー)→参照データ→判断→出力→人の承認、までを1本のフローとして定義する
理由3:データが散らばり、参照させたい情報に辿り着けない(RAG以前の問題)
RAG(Retrieval-Augmented Generation:社内データ検索で根拠を付けて回答する仕組み)をやりたいのに、そもそも「正」がどこにあるか不明、版管理がない、アクセス権が複雑——この状態だと精度以前に運用が破綻します。
- 失敗の兆候:回答の根拠リンクが出せない/古い手順書が混ざる/部署ごとに“正本”が違う
- 対策:データ分類(機密・社外秘・個人情報など)と、参照範囲(まずは限定)を決め、版管理・更新フローを置く
理由4:セキュリティとガバナンスが曖昧で、情報システム部門がGOを出せない
生成AI活用が止まる最大要因の一つがここです。論点は「危ないかどうか」ではなく、何をどう制御でき、監査で説明できるかです。
- 最低限押さえる論点
- 送信データ:機密/個人情報の扱い(マスキング、DLP等)
- 保存データ:プロンプト・回答・添付の保管、保持期間
- 学習利用:入力が学習に使われるか(契約・設定での扱い)
- 認証・権限:SSO(Single Sign-On)、MFA、多要素認証、RBAC(Role-Based Access Control)
- 監査ログ:誰が何を参照し、何を出力し、どのツールを実行したか
- 委託先管理:データ越境、契約条項
ここが曖昧なままだと、現場が勝手に使う“シャドーAI”が増え、むしろリスクが上がります。
理由5:既存システム連携が弱く、結局コピペで終わる(業務の中に入れない)
生成AIが本当に効くのは、社内のSaaS/オンプレ/データ基盤と繋がり、業務イベント(問い合わせ発生、申請作成、障害検知等)に反応できるときです。連携が無いと、利用者はブラウザで開いてコピペするだけになり、定着しません。
- 情報システム部門視点の要点:API連携/ファイル連携/イベント連携のどれで繋ぐか、失敗時のリトライ、監視、変更管理を最初から設計する
- 補足:iPaaS(Integration Platform as a Service)を使う場合は、コネクタの権限・監査ログ・スキーマ変更耐性まで含めて比較する
理由6:幻覚(ハルシネーション)対策が“注意喚起”止まりで、品質が担保できない
「AIの回答は間違うことがあります」では稟議は通りません。業務で使うなら、間違える前提で設計します。
- 有効な打ち手
- 根拠提示(参照元URL/文書ID/更新日)を必須にする
- 禁止領域の定義(法務判断・決裁・人事評価などは“提案”まで)
- 人の最終責任(承認ステップ)をワークフローに入れる
- 評価指標:正答率だけでなく、再現性、根拠一致率、差し戻し率を見る
理由7:運用設計が無く、属人化して止まる(更新・権限・監査・コスト)
PoCでは動いた。本番運用でも一度は動いた。でも、運用を行なっていく中でデータ更新で精度が落ちた、権限棚卸ができない、ログ保管コストが膨らんだ、モデル更新で挙動が変わった——運用で詰まります。
- 運用で必ず決めること
- 権限棚卸:誰が使えるか/どのデータにアクセスできるか(最小権限)
- ログ:保管期間、検索性、インシデント時の追跡手順
- 変更管理:プロンプト、参照データ、連携先APIの変更手順と承認
- コスト管理:実行回数、トークン、ログ保管、iPaaS実行、運用工数の見積り
“次の一手”の全体像:自社専用MCPサーバーで「業務に入る」と「統制する」を同時に満たす
ここまでの7つの理由は、突き詰めると2つに収れんします。
- 業務に入らない(連携・ワークフロー・データ参照が弱い)
- 統制できない(権限境界・監査・データ取扱いが曖昧)
この2つを同時に満たす設計として有力なのが、自社専用のMCPサーバーを用意するアプローチです。
MCP(Model Context Protocol)は、生成AIが業務ツールや社内データにアクセスするための“標準的な接続口”の一つです。ポイントは、生成AIに「何でも直接触らせる」のではなく、MCPサーバー側でツール実行やデータアクセスを仲介し、制御と監査を集約できることです。
MCPサーバーで改善できること(情報システム部門が嬉しい設計ポイント)
- ツール実行の権限境界:AIができる操作をツール単位・スコープ単位で制限(例:参照のみ、作成のみ、承認は不可)
- 接続先の管理:どのSaaS/DB/チケットシステムに繋ぐかを一元管理し、野良連携を防ぐ
- 認可・監査:誰が、どのデータにアクセスし、何を実行したかをログで追える(監査・インシデント対応で効く)
- 最小権限:トークン管理・スコープ設計をMCP側で統制し、過剰権限を減らす
- 運用しやすさ:接続先追加や変更を“サーバー側の変更管理”に寄せられる
つまり、生成AI活用が進まない企業が抱えがちな「現場に自由に使わせると怖い」「でも縛りすぎると使われない」の板挟みを、“安全に使える自由”として設計しやすくなります。
要件がまだ曖昧な段階でも、どこにMCPサーバーを置くべきか(ネットワーク分離、ID基盤連携、ログ基盤連携)、どのユースケースから始めるべきかを整理しましょう。
検討ポイント:セキュリティ/運用/コストを“項目レベル”で分解する
セキュリティ・ガバナンス
- データ分類:機密・個人情報・社外秘の取り扱い(送信可否、マスキング)
- 学習利用:入力・ログが学習に使われるか(契約・設定・保管場所)
- 認証:SSO、MFA、端末条件(条件付きアクセス等)
- 権限:RBAC、ツール実行の許可範囲、承認フロー
- 監査:プロンプト、参照データ、ツール実行、出力のログ(検索性含む)
- 秘密情報管理:APIキー、トークン、シークレットの保管とローテーション
- ネットワーク:社内システム接続の経路、分離環境、出口制御
運用
- 障害対応:連携失敗時のリトライ、手動復旧手順
- 変更管理:プロンプト/参照データ/コネクタ更新の申請・承認・リリース
- モデル更新:モデル切替時の品質検証(回帰テストの仕組み)
- 問い合わせ窓口:現場からの改善要望・誤回答報告の受け方
コスト(TCOの分解)
- モデル利用料:実行回数・トークン量・ピーク時の増分
- 連携基盤:iPaaS利用料、コネクタ費用、実行課金
- ログ保管:監査ログの保存・検索(期間で増える)
- 運用工数:権限棚卸、監視、変更管理、セキュリティレビュー
- 開発保守:ツール追加、スキーマ変更対応、回帰テスト
導入ステップ:PoC→本番運用で“止まらない”進め方
- ユースケース選定:業務インパクトが大きく、入力・参照・出力が定義しやすいものを1つに絞る
- 成功条件(KPI)定義:時間削減・一次回答率・差し戻し率など+誤出力率・運用問い合わせ件数
- データ範囲の限定:最初は「正本」が明確なデータに限定(版管理と更新フローもセット)
- 統制設計:SSO/RBAC/ログ/禁止領域/承認フローを最小構成で入れる
- 連携の最小実装:コピペではなく、チケット・申請・ナレッジ等の“業務の器”に入れる
- 評価→拡張:品質の回帰テストと運用負荷を見ながら、データとツールを段階的に増やす
よくある失敗と注意点
- 「万能チャットボット」から入る:対象業務が広すぎて評価不能。まずは業務フローが閉じた領域で始める
- ログを後回し:監査・インシデント時に説明できない。PoC段階から取得方針を決める
- 権限が強すぎる:AIに広いトークンを渡すと事故が起きる。最小権限とスコープ設計が基本
- コスト試算が“利用料”だけ:ログ保管・運用工数・連携基盤が後から効いてくる
判断のためのチェックリスト
- 目的:対象業務と「やらないこと」が明確か
- KPI:効果とリスク(誤出力等)の指標が定義されているか
- データ:参照データの正本・更新フロー・版管理があるか
- セキュリティ:データ分類、送信/保存/学習の扱いが説明できるか
- 認証・権限:SSO/MFA/RBAC、最小権限の設計があるか
- 監査:プロンプト・参照・ツール実行・出力のログが取れるか
- 運用:変更管理、障害時の復旧手順、問い合わせ窓口があるか
- 連携:業務システム(チケット/申請/CRM等)に組み込めるか
- コスト:利用料+連携基盤+ログ+運用工数のTCOで見ているか
- 責任分界:人の最終責任(承認)と、AIの適用範囲が定義されているか
まとめ:進まないのは能力不足ではなく“業務・統制・自社観点の設計不足”
生成AI活用が進まない理由は、PoCの目的不在、刺さるユースケース不在、データ未整備、ガバナンス不明確、連携不足、品質担保不足、運用不在——の7つに整理できます。
裏返すと、業務に入る連携と統制できる仕組みが揃えば、生成AIは「まだ早い」から「条件が揃えば使える」に変わります。その実装パターンの一つが、自社専用MCPサーバーでツール実行とデータアクセスを仲介し、権限・監査・運用を設計可能にするアプローチです。
SaaS連携基盤なら「JOINT」にお任せください
ストラテジットは 「AIとSaaSの力をすべての企業に」 をミッションに、連携ツールであり連携基盤でもあるJOINT シリーズを展開しています。
まずは “どんな連携が可能か知りたい” という段階でも、お気軽にご相談ください。
- SaaSベンダー向けiPaaS「JOINT iPaaS for SaaS」
SaaSベンダーが自社製品に連携機能を簡単に組み込めるEmbedded iPaaS - SaaS利用者向けiPaaS「JOINT iPaaS for Biz」
SaaS利用企業向けのデータ連携・業務自動化ソリューション - 生成AI連携基盤「JOINT AI Flow」
AIが必要なデータを探し出し、業務フローに沿ってつなげる新しいAI連携サービス
これらのソリューションを通じて、ベンダー・利用企業双方に「つながる価値」を提供します。
自社SaaSの満足度を上げたいSaaSベンダー様、まずは話だけでも聞いてみたいといった企業様は、ストラテジットが提供する 『JOINT』プロダクトを是非ご検討ください。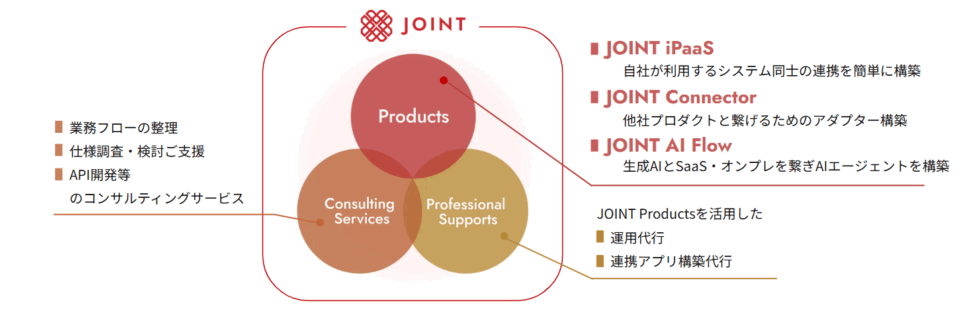
シェアする







