RAGとMCPの違いとは?|精度設計とコンテキスト連携・ログの考え方
企業で生成AIを業務実装しようとすると、「RAG(Retrieval-Augmented Generation:検索拡張生成)をまず作るべきか」「MCP(Model Context Protocol)でコネクタ連携を整えるべきか」で議論が分かれがちです。
結論から言うと、RAGは“知識の正確な参照”の仕組み、MCPは“外部システムやツールへ安全に繋ぐための接続・実行の枠組み”で、得意領域が異なります。
この記事では、情報システム部門主導で稟議・設計に進めるために、次の判断材料を整理します。
- RAGとMCPの違い(適用範囲/できること・できないこと)
- RAGシステムで精度を上げる具体策(データ設計、検索設計、評価・運用)
- MCPでのコンテキスト連携・ログ評価・コネクタ設計(LangChain活用を含む実装観点)
本記事はRAGを主役に、MCPとの境界と設計論点を深掘りします。

目次
- 1 情報システム部門視点の背景:生成AIは「回答品質」より先に「データと接続の責任」が問われる
- 2 RAGとMCPの違い:比較表(情報システム部門としての判断軸)
- 3 RAGとは何か:利用者向けに「どこで精度が決まるか」だけ押さえる
- 4 RAGシステムで精度を上げる方法:設計の打ち手を「再現性ある項目」に落とす
- 5 MCPはどこで効くのか:RAGでは埋まらない「実行」と「接続」の論点
- 6 RAG×MCPの全体像:コンテキスト連携の「責任分界」を決める
- 7 ログ設計と評価方法:RAGとMCPは“同じログ基盤”で見ると運用が楽になる
- 8 コネクタ設計(LangChain活用を含む):壊れにくい連携にするための要点
- 9 セキュリティ・ガバナンス:RAGとMCPで“守る場所”が違う
- 10 コスト(TCO)の考え方:RAGは“データと評価”、MCPは“運用と監査”が効いてくる
- 11 向く/向かない:判断を早める目安
- 12 導入ステップ:PoCから本番まで(情報システム部門が主導して導入しても失敗しない進め方)
- 13 よくある失敗と回避策
- 14 判断のためのチェックリスト(社内資料に転用可)
- 15 まとめ:RAGは“正しく参照する仕組み”、MCPは“安全に繋いで実行する仕組み”
- 16 SaaS連携基盤なら「JOINT」にお任せください
情報システム部門視点の背景:生成AIは「回答品質」より先に「データと接続の責任」が問われる
社内で生成AIを展開する際、現場は「回答が当たるか」を重視します。一方で情報システム部門では、次の論点で止まりやすいはずです。
- 機密情報・個人情報をどこまでモデルへ送るのか(送信/保存/学習の扱い)
- 権限(SSO/MFA、RBAC、最小権限、データアクセス制御)をどう担保するか
- 監査ログ(誰が何を参照し、どのツールを実行したか)をどう残すか
- 運用(データ更新、検索精度の劣化、コネクタ変更、障害時の切り分け)を回せるか
この観点で見ると、RAGは「社内知識を正確に参照する」ための設計が中心になり、MCPは「社内外ツールを安全に呼び出す」ための境界設計が中心になります。両者は競合というより、“検索(RAG)”と“実行(MCP)”の役割分担として整理すると意思決定が進みます。
RAGとMCPの違い:比較表(情報システム部門としての判断軸)
| 観点 | RAG(検索拡張生成) | MCP(Model Context Protocol) |
|---|---|---|
| 主目的 | 社内文書・ナレッジを検索して根拠を付けて回答する | 外部システム/ツールへ安全に接続し、必要な操作や取得を行う |
| 中心となる設計 | データ整備、分割(chunk)、埋め込み、検索(ベクトル/キーワード)、再ランキング、評価 | コネクタ(ツール)の設計、認可、実行制御、監査ログ、接続先管理 |
| 成果物イメージ | 「根拠リンク付き回答」「社内規程の検索回答」など | 「チケット作成」「経費精算状況取得」「SaaSデータ更新」など |
| 失敗しやすい点 | データが汚い/古い、検索が外れる、評価が曖昧で改善できない | 権限過大、ログ不足で追跡不能、接続先変更に弱い、誤実行対策がない |
| 向くユースケース | FAQ、規程・マニュアル、技術ドキュメント、営業資料検索 | 業務システム横断の自動化、AIエージェントのツール実行、複数SaaS連携 |
RAGとは何か:利用者向けに「どこで精度が決まるか」だけ押さえる
RAGは、生成AIのモデルが持たない(または最新ではない)社内知識を、検索結果としてコンテキストに入れて回答させる方式です。精度は「モデルの賢さ」だけでなく、検索で何を持ってくるかで大きく変わります。
実務上は、RAGを次のパイプラインとして分解すると設計・責任分界が明確になります。
- 取り込み:SharePoint/Confluence/ファイルサーバ等から収集
- 整形:OCR、表の正規化、不要情報の除去、メタデータ付与
- 分割(chunking):段落・見出し単位などで分割
- 索引化:ベクトル化(埋め込み)+必要に応じてキーワード索引
- 検索:フィルタ(部門/権限/機密区分)+上位候補抽出
- 再ランキング:候補を質問に近い順に並べ替え
- 生成:根拠を引用し、回答を構成
- 評価・改善:ログと指標で継続改善
RAGシステムで精度を上げる方法:設計の打ち手を「再現性ある項目」に落とす
データ側で効く:正解データは「本文」より「メタデータ」と「鮮度」
RAGの精度改善は、モデル変更よりも先にデータ整備で大きく伸びることが多いです。情報システム部門が押さえるべきポイントは次の通りです。
- 版管理:改定日・版数をメタデータ化し、古い版を検索に出さない(または優先度を下げる)
- 機密区分:公開/社内/部門限定/秘などのラベルを付与し、検索時にフィルタできるようにする
- 所有者(オーナー):文書の責任部署を付け、問い合わせ先や更新フローに繋げる
- ノイズ除去:フッターの定型文、目次の重複、OCR誤認識などを可能な範囲で抑える
検索側で効く:ハイブリッド検索+フィルタ+再ランキングが現実解
「ベクトル検索だけ」では、略語・製品名・型番などで外れやすいケースがあります。業務RAGでは、次の組み合わせが安定しやすいです(要件とデータ特性に依存します)。
- ハイブリッド検索:ベクトル(意味)+キーワード(用語一致)
- メタデータフィルタ:部門、システム、機密区分、文書種別、期間など
- 再ランキング:上位候補をLLMや専用モデルで並べ替え、根拠の“取り違え”を減らす
プロンプト側で効く:「根拠の出し方」を固定し、幻覚を運用で抑える
情報システム部門の関心は、利用者むけに回答の自然さより誤回答の抑制です。RAGでは、プロンプトで次を固定すると運用しやすくなります。
- 根拠提示:引用元(文書名・URL・改定日)を必須にする
- 不明時の挙動:「根拠が不足なら回答しない/追加質問する」を明示
- 出力の型:手順・注意事項・対象範囲など、社内文書の説明に向くテンプレを統一
評価で効く:RAGは「作って終わり」にすると劣化する
検索対象が更新される以上、RAGは放置すると劣化します。最低限、次のKPIを継続観測できるようにします。
- 回答一次解決率(追加問い合わせが不要だった割合)
- 根拠一致率(正しい文書を引けているか:人手評価/サンプル監査)
- 検索ヒット率(該当文書があるのに取れないケース)
- 運用KPI:インデックス更新遅延、失敗ジョブ件数、問い合わせ対応工数
この評価設計が曖昧なままPoCを始めると、「雰囲気で良さそう」止まりになり本番運用ののせる判断ができません。要件が固まっていない段階でも、評価指標の棚卸しから行うことで現実的に利用可能な範囲が見えてきます。
MCPはどこで効くのか:RAGでは埋まらない「実行」と「接続」の論点
RAGは基本的に「読む」仕組みです。一方、AIエージェント運用では「チケット登録」「ワークフロー起動」「台帳更新」など、書く・実行する要求が増えます。そこでMCPの設計論点が前面に出ます。
ここでは詳細説明は避けつつ、RAGと接続して情報システム部門が検討すべき要点だけ挙げます。
- 権限境界:モデルが勝手にツールを実行しないよう、許可された操作・スコープに限定する
- 接続先管理:どのSaaS/オンプレへ繋ぐか、環境分離(開発/本番)、変更管理
- 監査ログ:誰がどの要求で、どのツールを、どのパラメータで実行したか
- 秘密情報管理:APIトークン、OAuthクライアント、鍵の保管とローテーション
RAG×MCPの全体像:コンテキスト連携の「責任分界」を決める
実装・運用を安定させるには、RAGとMCPを次のように役割分担させるのが分かりやすいです。
- RAG:社内文書から根拠を集め、「判断材料」と「手順」を提示する
- MCP:提示された手順のうち、許可された範囲で「実行(作成/更新/起動)」を担当する
例えば「経費精算の差戻し理由を調べて、申請者へ案内文を作り、必要ならチケットを起票する」では、RAGが規程・過去事例・テンプレを引き、MCPがチケット起票やSaaS参照を担います。
ログ設計と評価方法:RAGとMCPは“同じログ基盤”で見ると運用が楽になる
情報システム部門が本番運用を担当する上で困るのは「何が起きたか追えない」状態です。RAGとMCPはログ観点が異なるため、最初にログの粒度を揃えておくと監査・障害対応が一気に楽になります。
最低限残したいログ項目(例)
- ユーザー:誰が(SSOの主体、部門、ロール)
- 入力:質問文(機密対策でマスキング/要約保存も検討)
- RAG検索:検索クエリ、フィルタ条件、ヒット文書ID、スコア、再ランキング結果
- 生成:回答、引用(根拠)一覧、モデル/バージョン、トークン量
- ツール実行(MCP側):ツール名、実行可否、パラメータ、戻り値、エラー、実行時間
- ガードレール:DLP/ポリシー違反判定、ブロック理由、承認フローの有無
評価の切り口:品質・再現性・安全性・コストを分ける
- 品質:正答率、根拠の適切性、引用漏れ、一次解決率
- 再現性:同じ質問で結果がぶれないか(検索・再ランキング・プロンプトの固定)
- 安全性:権限外データ参照が起きていないか、誤実行がないか、監査で説明できるか
- コスト/性能:応答時間、ピーク時スループット、トークン/検索回数、ログ保管費
コネクタ設計(LangChain活用を含む):壊れにくい連携にするための要点
LangChainのようなフレームワークを使うと、RAG(retriever)やツール呼び出し(tools)を構成要素として組み立てられます。ただし、フレームワークはあくまで“実装の手段”で、情報システム部門が見るべきは次の設計です。
コネクタの責任分界:最小権限・入力検証・冪等性
- 最小権限:読み取り専用・対象プロジェクト限定などスコープを絞る
- 入力検証:自然言語から生成されたパラメータをそのまま実行しない(型・桁・許容値)
- 冪等性:再実行で二重登録が起きない設計(リトライ、DLQ、実行ID)
運用で効く:変更管理と監視(iPaaS的な観点を取り込む)
- 監視/アラート:失敗率、遅延、外部APIのレート制限
- スキーマ変更耐性:SaaS APIの項目変更に備えた契約テスト/ヘルスチェック
- 環境分離:開発/検証/本番の接続先・トークンを分ける
セキュリティ・ガバナンス:RAGとMCPで“守る場所”が違う
稟議で刺さる論点を、RAGとMCPで分けて整理します(最終判断は社内規程・法務/セキュリティ部門と要確認)。
RAG側(主に「参照」の統制)
- データ分類(機密・個人情報)と検索フィルタ、アクセス制御(RBAC)
- 送信/保存:プロンプトに何が入るか、ログに何を残すか(マスキング方針)
- 根拠提示:監査・説明責任のため、引用元を出せる設計
MCP側(主に「実行」の統制)
- ツール実行の制御:許可された操作だけを公開、承認フローの導入可否
- 秘密情報管理:トークンの保管/ローテーション、漏えい時の影響範囲
- 監査ログ:実行履歴(誰が何をしたか)と追跡可能性
コスト(TCO)の考え方:RAGは“データと評価”、MCPは“運用と監査”が効いてくる
金額は環境・規模で変わるため断定しませんが、稟議ではコスト項目を分解して説明すると通りやすくなります。
- モデル利用:トークン課金、同時実行、応答時間要件によるモデル選定
- 検索基盤:ベクトルDB/検索サービス、インデックス更新、ストレージ
- データ整備:取り込みパイプライン、OCR、メタデータ付与、版管理
- 評価・改善:評価データ作成、定期レビュー、A/Bテスト、監査サンプル
- コネクタ運用:接続先追加、API変更対応、監視、障害対応(MCP/ワークフロー)
- ログ保管:保管期間、マスキング、SIEM連携、監査対応工数
向く/向かない:判断を早める目安
RAGが向く
- 規程・マニュアル・技術資料など「社内に答えがある」が探せていない
- 回答に根拠提示が必須(監査・品質要求がある)
- 更新頻度があり、検索精度を評価して改善する体制を作れる
MCP(ツール連携)が向く
- AIに「参照」だけでなく「作成/更新/起動」までさせたい
- SaaS/オンプレを跨いだ連携が多く、権限・ログ・変更管理がボトルネック
- エージェント実行の監査要件があり、ツール実行ログが必要
慎重にすべき条件(どちらにも共通)
- 監査要件が厳しいのに、ログ保管や追跡の設計ができていない
- データ分類(機密/個人情報)が未整備で、検索対象が決められない
- 運用責任(文書オーナー、更新、例外対応)が宙に浮いている
導入ステップ:PoCから本番まで(情報システム部門が主導して導入しても失敗しない進め方)
PoC(4〜8週間の例):目的を「精度」だけにしない
- 対象業務を絞る:問い合わせが多い領域、文書が比較的整っている領域から
- 成功条件を定義:一次解決率、根拠一致率、応答時間、誤実行ゼロなど
- ログと評価を先に作る:改善サイクルが回るかを検証する
- 権限設計の検証:部門限定文書が漏れないか、ツール実行が暴走しないか
本番:データ更新・権限棚卸・モデル更新を運用に組み込む
- 更新フロー:文書改定→反映(インデックス更新)→検証→リリース
- 権限棚卸:四半期/半期でロールと検索対象の見直し
- インシデント対応:誤回答・情報漏えい疑い・誤実行の手順化
よくある失敗と回避策
- 失敗:RAGの精度が上がらない
回避:データ整備(版/メタデータ)、ハイブリッド検索、再ランキング、評価データ整備を優先する - 失敗:PoCが「便利そう」で終わる
回避:KPI(品質/再現性/安全性/コスト)を分け、ログで測る - 失敗:ツール連携で事故が怖くて止まる
回避:最小権限、入力検証、承認フロー、実行ログを前提にMCP/コネクタを設計する - 失敗:費用対効果が合わない
回避:なんでも生成AIに任せるわけでなく、検索ワードや事例、達成すべき効果を見極めて、必要なところを見極めた設計を行う
判断のためのチェックリスト(社内資料に転用可)
- RAG検索対象のデータ分類(機密/個人情報)と範囲が決まっている
- 文書に改定日・版・所有者のメタデータを付与できる
- 評価指標(一次解決率、根拠一致率、誤回答率)を定義した
- 検索の権限制御(SSO/RBAC)と監査ログ方針がある
- ツール連携が必要な場合、最小権限と実行制御(承認/禁止操作)が設計できる
- 運用(更新、監視、障害対応、変更管理)の担当と手順が置ける
- コストを項目分解し、TCO(運用工数・ログ保管含む)で説明できる
まとめ:RAGは“正しく参照する仕組み”、MCPは“安全に繋いで実行する仕組み”
RAGとMCPは「どちらが上」ではなく、RAGは“正しく参照する仕組み”、MCPは“安全に繋いで実行する仕組み”として役割が異なります。まずはRAGで根拠提示と評価サイクルを作り、業務要件が「実行」に広がる段階でMCP(コネクタ・ログ・権限)を強化すると、稟議・運用の筋が通りやすくなります。
SaaS連携基盤なら「JOINT」にお任せください
ストラテジットは 「AIとSaaSの力をすべての企業に」 をミッションに、連携ツールであり連携基盤でもあるJOINT シリーズを展開しています。
まずは “どんな連携が可能か知りたい” という段階でも、お気軽にご相談ください。
- SaaSベンダー向けiPaaS「JOINT iPaaS for SaaS」
SaaSベンダーが自社製品に連携機能を簡単に組み込めるEmbedded iPaaS - SaaS利用者向けiPaaS「JOINT iPaaS for Biz」
SaaS利用企業向けのデータ連携・業務自動化ソリューション - 生成AI連携基盤「JOINT AI Flow」
AIが必要なデータを探し出し、業務フローに沿ってつなげる新しいAI連携サービス
これらのソリューションを通じて、ベンダー・利用企業双方に「つながる価値」を提供します。
自社SaaSの満足度を上げたいSaaSベンダー様、まずは話だけでも聞いてみたいといった企業様は、ストラテジットが提供する 『JOINT』プロダクトを是非ご検討ください。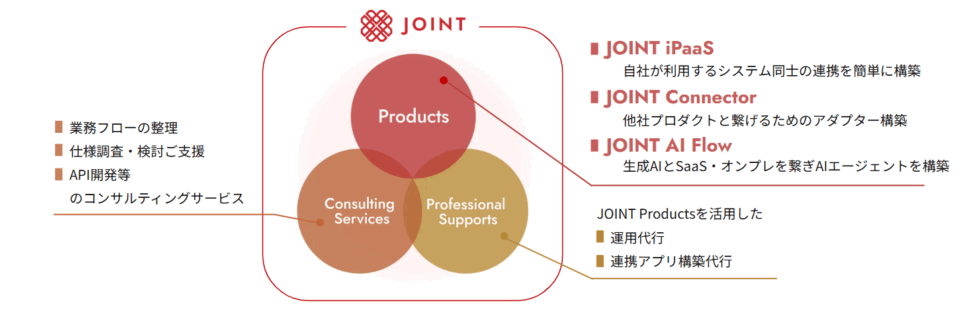
シェアする